Basi di Dati - Progettazione e Normalizzazione
In questo articolo andrò ad illustrare i punti chiave della progettazione di basi di dati e della normalizzazione, nonchè andare a risolvere esercizi d’esame per preparazione alla prova del 26 Gennaio.
Bibliografia:
- Fondamenti di Basi di Dati, A.Albano, G.Ghelli, R.Orsini
- Dispense corso Basi di Dati - UniCT L31 Informatica - Prof. A.Pulvirenti
Progettazione
La progettazione di una base di dati è una sistematizzazione del processo di realizzazione e modellazione di un sistema.
Fondamentalmente divisibile in progettazione concettuale e logica, i due tipi di progettazione interdipendenti si distinguono dalla presenza di un vero e proprio schema concettuale, con collegamenti, relazioni ed entità nella progettazione concettuale (es: Modello Entità-Relazione), mentre in quella logica è caratterizzante la presenza di Entità con attributi e chiavi.
Durante la progettazione di una base di dati si viene provvisti di un testo dal quale strutturare le informazioni. E’ importante leggerlo attentamente, in modo da modellarne correttamente entità, relazioni e attributi. Andiamo a vedere l’esempio delle lezioni 2018 del Politecnico di Torino: Esercizi di progettazione concettuale e logica.
Durante la lezione viene svolto un esercizio sulla realizzazione di una base di dati per la gestione dei Telepass presso le autostrade italiane.

Se vi sembra un esercizio troppo complesso, o troppo lungo, sappiate che più informazioni avete sul database e i suoi oggetti, più sarà facile stilare la progettazione nel modo corretto.
Modellazione Entità
Nel corso delle prime letture del testo sarà di fondamentale importanza carpire e illustrare le entità che saltano all’occhio, e collegarle tra loro attraverso relazioni in una prima bozza del modello.

In questa prima parte del testo si evincono due entità: autostrada e casello, collegate tra loro dalla relazione ‘casello appartiene a autostrada’.
Proviamo quindi a fare le prime due bozze di entità CASELLO e AUTOSTRADA con le informazioni fornite dal testo.
| CASELLO |
|---|
| codice_casello |
| codice_autostrada |
| AUTOSTRADA |
|---|
| codice_autostrada |
| nome_autostrada |
| lunghezza_km |
Fatte le due tabelle, e selezionate propriamente le chiavi (in grassetto), notiamo subito alcune proprietà delle entità che trattiamo. Un casello infatti non ha un singolo attributo come chiave, bensì due: il codice che lo identifica all’interno dell’autostrada, ed il codice dell’autostrada stessa. Abbiamo una relazione tra Casello e Autostrada che segneremo come un rombo tra le due tabelle.
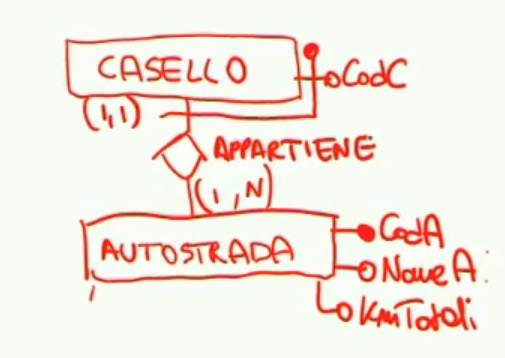
Bene, notiamo subito due cose non discusse:
- Il verbo ‘Appartiene’ è il ‘nome’ della relazione, alcune relazioni hanno inevitabilmente attributi o tabelle proprie (vedremo più avanti);
- Le coppie di numeri tra parentesi vicino alla relazione sono chiamate “Cardinalità” relazionali. Vanno definite in ogni relazione, da entrambi i ‘lati’ del collegamento.
Cardinalità
La cardinalità è un argomento complesso da comprendere se non ci si è mai addentrati nella progettazione di database.
Per dare una definizione informale e mirata alla comprensione del concetto, posso dire che la cardinalità per l’esempio precedente è una coppia di numeri che risponde alla domanda: “Data l’entità Casello, quante relazioni di Appartenenza può formare con autostrada? quanti caselli prevede di descrivere la relazione?”, se considero la relazione da casello ad autostrada, avrò come risposta che ogni casello sarà associato ad un unica relazione di appartenenza con autostrada (1,1).
Se cerco la cardinalità della relazione da autostrada a casello, dovrei chiedermi qualcosa come: “Avendo l’entità autostrada, quanti relazioni di appartenenza a caselli può formare? quante autostrade prevede di descrivere la relazione?”. La risposta sarà che ad ogni autostrada potrò avere un numero N di relazioni appartenenza con caselli (relazione uno a molti) (1,N).
I numeri nella cardinalità di relazione quindi, possono essere descritti nel seguente modo: (x,y) -> x : numero entità descritte nell’insieme di partenza y : numero di relazioni possibili nell’insieme di arrivo
Continuiamo con la progettazione del database.
Generalizzazione Entità
Andiamo al punto 2 del problema. 
Commentando le cardinalità di questo sistema, vediamo come per ogni Telepass descritto possa esistere un solo un titolare, mentre un utente può essere titolare di N telepass.
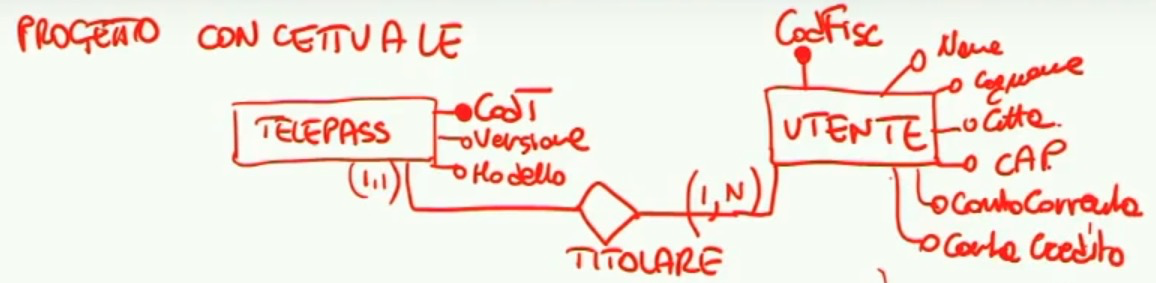
Prendendo invece il punto 3 dell’esercizio troviamo una richiesta particolare per l’entità veicolo: 
La richiesta si soddiasfa se ogni tipo di veicolo è descrivibile. Noteremo come veicolo è la generalizzazione delle entità figlie specifiche: “Automobile”, “ Motocicletta”, “Furgone” e “Camion”.
Le generalizzazioni hanno due proprietà nella progettazione di basi di dati.
Una generalizzazione può esere totale o parziale. Una generalizzazione è totale quando ogni istanza dell’entità padre è sempre istanza di almeno un’entità figlia, parziale se esiste almeno un’istanza dell’entità padre che non fa parte di nessuna entità figlia.
Una generalizzazione può essere di tipo esclusivo o sovrapposto. Esclusivo se ogni istanza dell’entità padre rientra in una e una sola entità figlia, sovrapposto se c’è almeno un’istanza che appartiene a più entità figlie
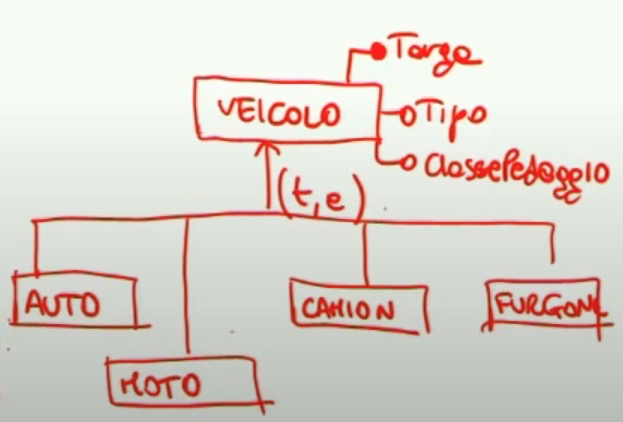 notiamo come questa generalizzazione è di tipo totale ed esclusivo (t,e)
notiamo come questa generalizzazione è di tipo totale ed esclusivo (t,e)
Collegamenti tra entità
Rileggendo la prima frase del punto 3, notiamo come un telepass sia valido per uno o più veicoli. Come definiamo dunque la relazione tra veicoli e telepass?
Un telepass è valido per uno o più veicoli.
Quindi per ogni telepass avremo N relazioni di validità per un numero di veicoli sconosciuto (1,N), mentre dato un veicolo può essere associato uno o più telepass (1,1)(1,N). 1,N non è sbagliato perchè in un veicolo possono essere usati telepass diversi (pensa a marito e moglie). 1,1 non è sbagliato perchè si può dare per scontato che ad un veicolo sia collegato solo un utente.
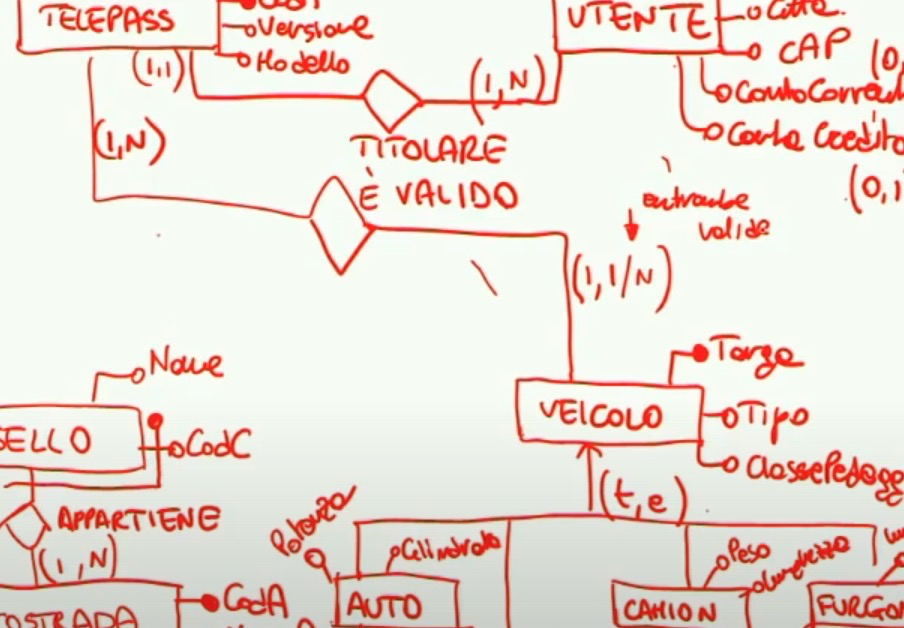
Punto 4
Terminiamo la progettazione concettuale con l’ultimo punto. 
Normalizzazione
La teoria della normalizzazione si occupa dei seguenti problemi:
- Definire quando due schemi sono equivalenti
- Definire quando uno schema è migliore di un altro
- Definire metodi algoritmici per l’ottimizzazione di schemi
Per comprendere i concetti di normalizzazione bisogna definire alcune proprietà stesse della progettazione di basi di dati.
L’ipotesi che è alla base della normalizzazione assume che uno schema relazionale è descrivibile nella sua interezza attraverso un unico schema di relazione universale.

Dipendenza funzionale
Costruiamo un esempio di un insieme di generiche dipendenze funzionali. Dato uno schema relazionale R(T), una dipendenza funzionale è definita come una relazione tra più attributi.
Avendo uno schema relazione del tipo R(A,B,C,D,E) le dipendenze funzionali sono le possibili relazioni tra gli attributi A,B,C,D,E. Supponiamo ipoteticamente che A e C siano in relazione, in modo che A implica C, e che invece l’attributo B implichi l’attributo D. Queste relazioni prese singolarmente si definiscono come dipendenze funzionali. Avremo allora l’insieme delle dipendenze funzionali dello schema R: F = {AC -> E, B -> D}